安装教程
1. 效果演示
生成视频演示:
效果演示:
2. 使用视频
一键包启动后演示界面:
3. 图文教程
3.1 整合包下载
3.2 解压缩启动
解压:
打开文件来到根目录,双击go-webui.bat打开:
如果没有.bat的后缀可以在查看里打开文件扩展名,后面也会遇到很多需要后缀的:
这就是正常打开了,稍加��等待就会弹出网页,如果没有弹出网页可以复制命令行的链接,在浏览器里打开即可。
这就是网页端,注意程序运行的时候不要关闭命令行。
3.3 数据集准备
数据集不在多,1分钟的优秀数据集都可以训练出非常好的模型。关键是数据集的质量要好,要口齿清晰,无噪音最好。如果有伴奏或者背景音乐就一定要先用UVR做人声分离。
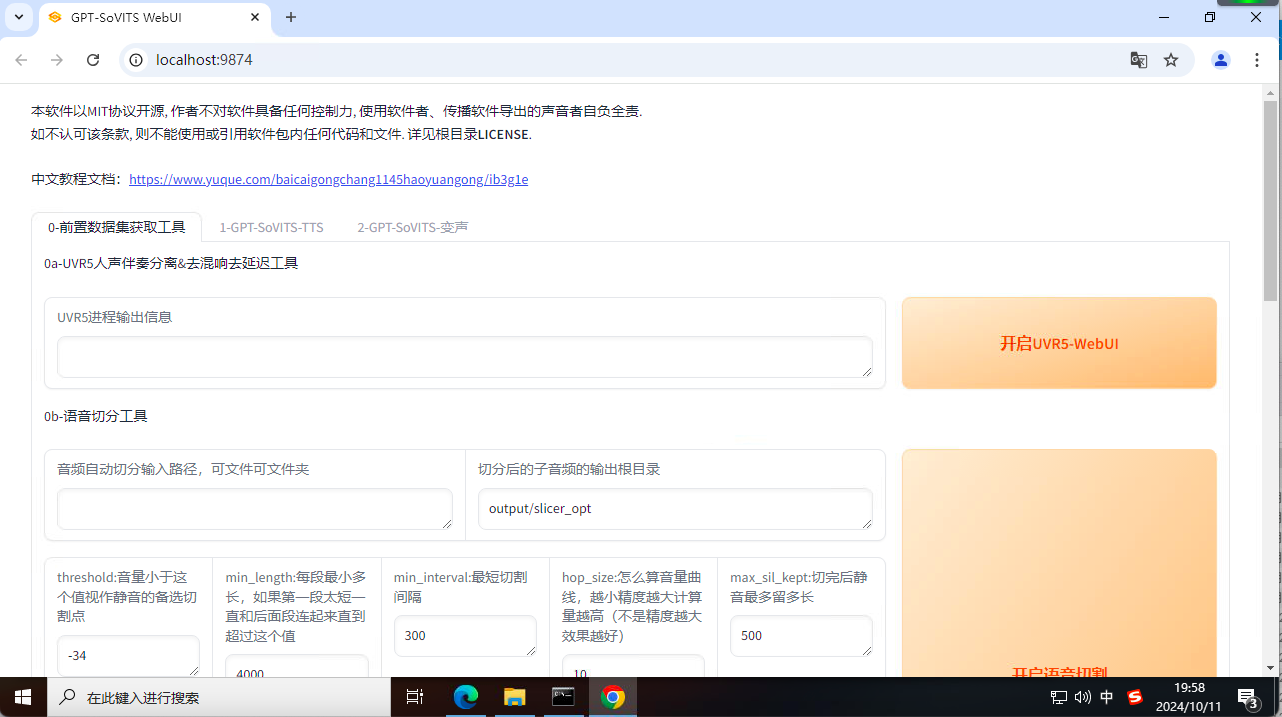
3.3.1 使用UVR进行人声分离
点击使用UVR5-WebUI稍等就会打开UVR的网页,如果没有打开,可以在浏览器里打�开:http://0.0.0.0:9873,或者命令行里回车,然后复制最后一个链接,在浏览器里打开即可。
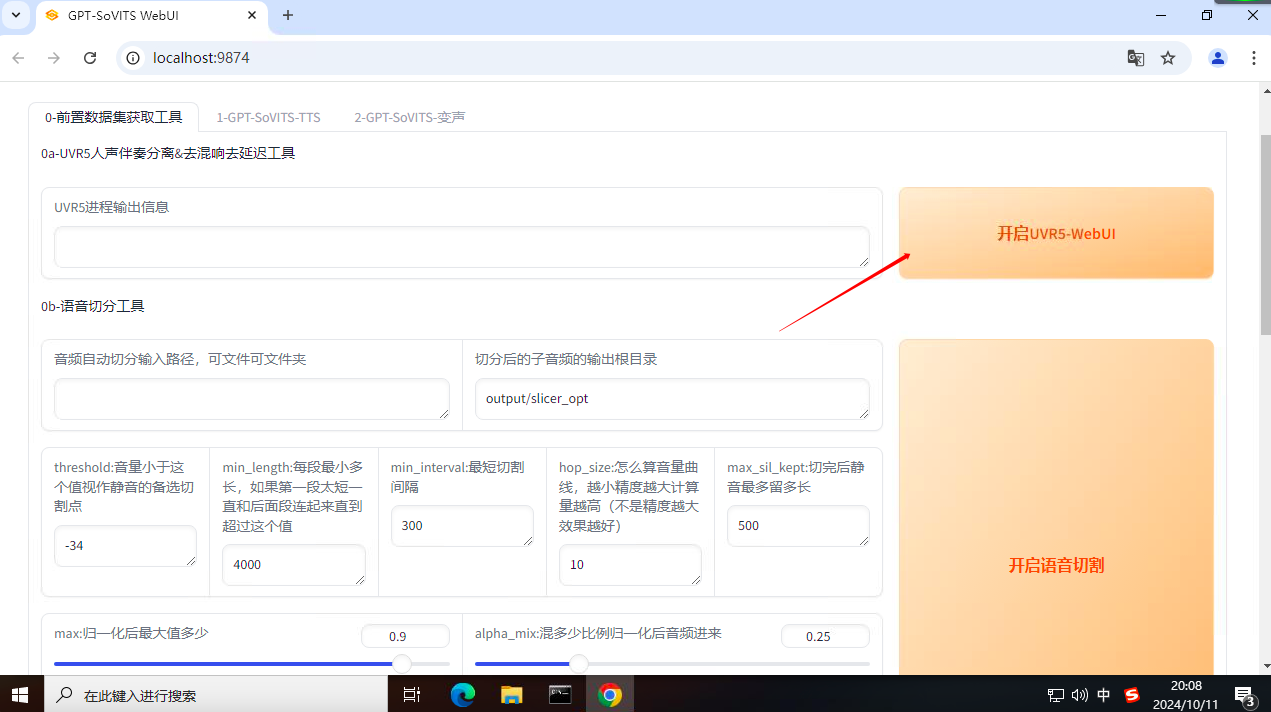
这就是UVR的网页端
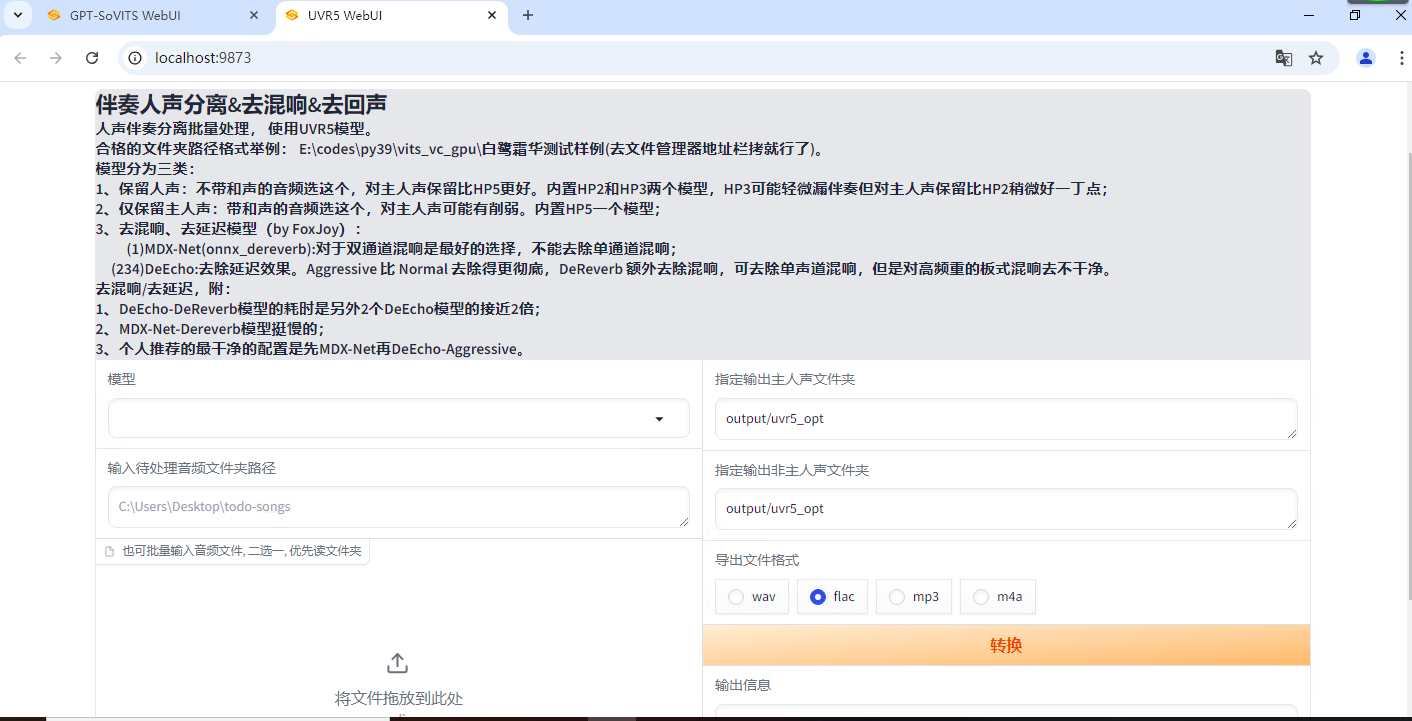
推荐选择文件夹路径,把声音文件所在的文件夹路径复制,输入进去。
然后进行下面3步:
- 用HP2_all_vocals模型提取人声
- 对提取出的人声使用onnx_dereverb进行增强
- 最后对增强后的声音进行DeEcho-Aggressive去混响
输出的文件默认在GPT-SoVITS-beta\output\uvr5_opt这个文件夹下。处理完的音频(vocal)的是人声,(instrument)是伴奏,其他都可以删除。结束后记得到WebUI关闭UVR5节省显存。
3.3.2 切割音频
这一步非常重要,字幕和音频的匹配要准确,直接影响最后的模型效果
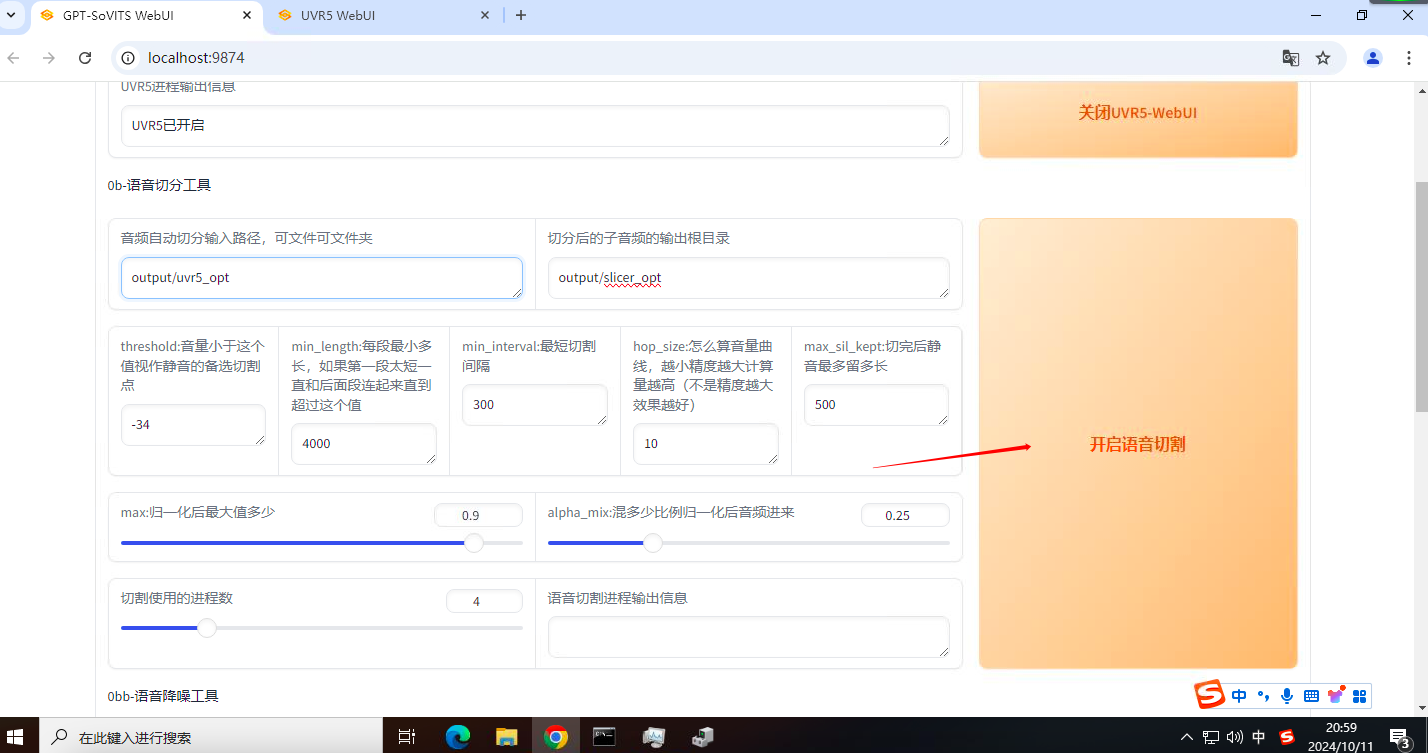
首先输入原音频的文件夹路径(不要有中文),如果刚刚经��过了UVR5处理那么就是uvr5_opt这个文件夹。然后建议可以调整的参数有min_length、min_interval和max_sil_kept单位都是毫秒。
- min_length 切割的最小时长,根据显存大小调整,显存越小调越小,一般保持默认即可。
- min_interval 切割的最小时间间隔,根据音频的平均间隔调整,如果音频太密集可以适当调低,一般保持默认即可。
- max_sil_kept 切割连贯性,不同音频不同调整,一般保持默认即可。
- 其他参数保持默认即可。
点击“开启语音切割”,马上就切割好了。默认输出路径在output/slicer_opt:
- 如果遇到切割后的音频文件太长,为了避免后一步爆显存,要么就丢弃这个音频,要么就用其他软件再手动切割一下。
- 如果语音切割后还是一个文件,那是因为音频太密集了,可以调低min_interval解决这个问题
3.3.3 降噪(可以跳过)
如果你觉得你的音频足够清晰可以跳过这步,降噪对音质的破坏挺大的,谨慎使用。
输入刚才切割完音频的文件夹,默认是output/slicer_opt文件夹。然后点击”开启语音降噪“。默认输出路径在output/denoise_opt。
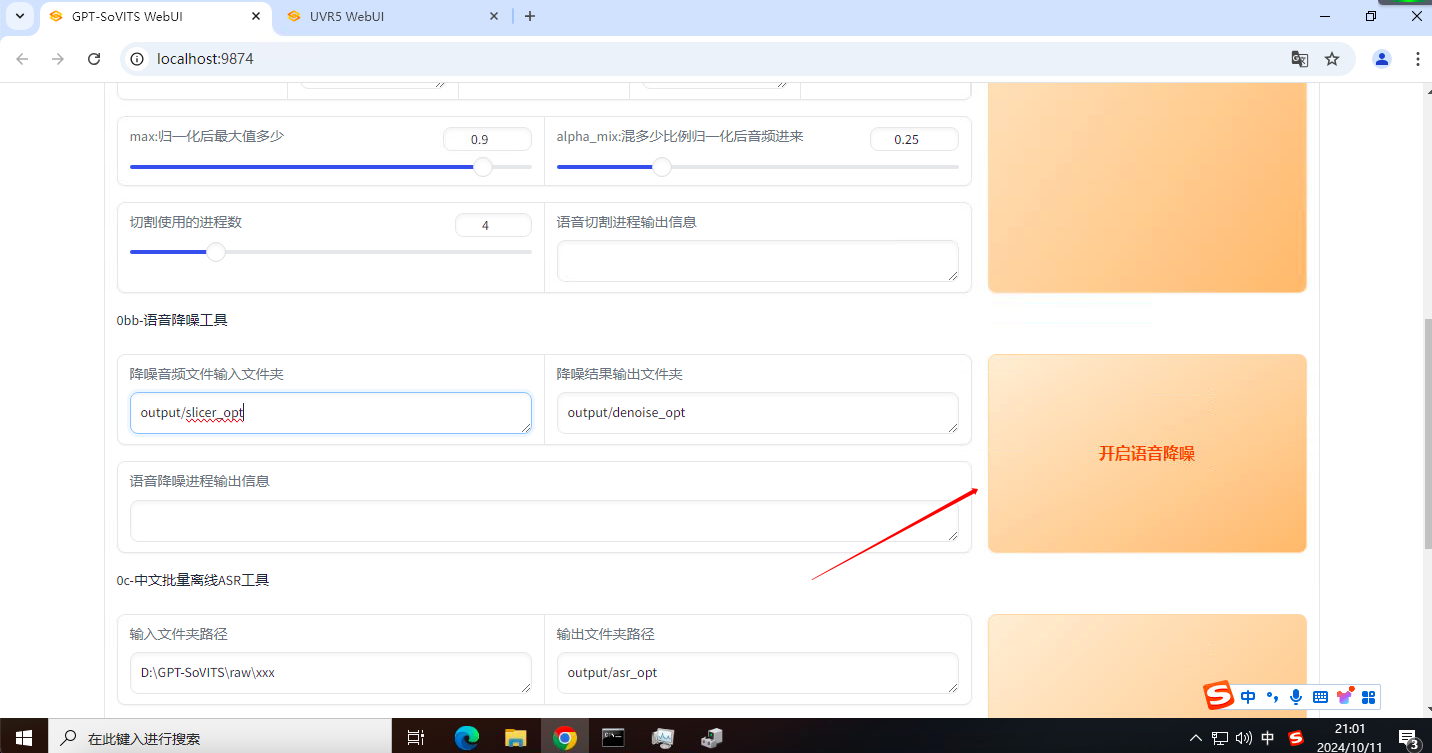
3.3.4 字幕对齐
如果你上一步切分了或者降噪了,那么已经自动帮你填充好路径了。如果你是通过其他软件做的音频质量优化,把处理完的音频的路径复制进来。
- 如果原始素材是汉语和粤语,推荐选择达摩ASR模型,效果也最好。
- 如果是英语,日语,推荐选择fast whisper模型,fast whisper可以标注99种语言,是目前最好的英语和日语识别,模型尺寸选large V3,语种选auto自动。
然后点"开启离线批量ASR"就好了,默认输出是output/asr_opt这个路径。ASR需要一些时间,看着控制台有没有报错就好了
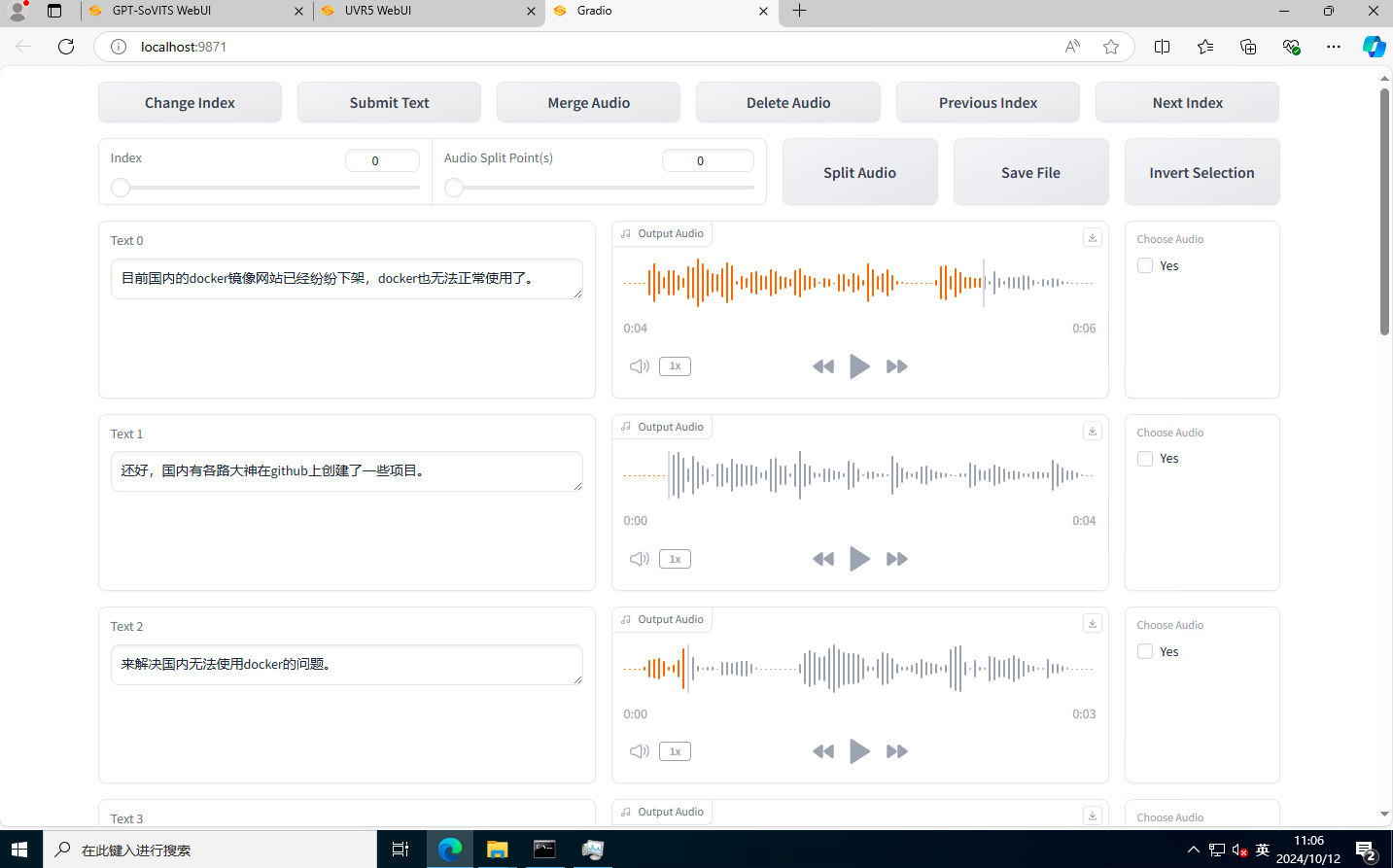
上一步ASR完会自动填写list路径,你只需要点击开启"打标webui"
打开后就是SubFix,从左往右从上到下依次意思是:跳转页码、保存修改、合并音频、删除音频、上一页、下一页、分割音频、保存文件、反向选择。每一页修改完都要点一下保存修改(Submit Text),如果没保存就翻页那么会重置文本,在完成退出前要点保存文件(Save File),做任何其他操作前最好先点一下保存修改(Submit Text)。删除音频先要点击要删除的音频右边的yes,再点删除音频(Delete Audio)。删除完后文件夹中的音频不会删除但标注已经删除了,不会加入训练集的。
3.4 训练
点击一下第二个界面,进入训练界面。
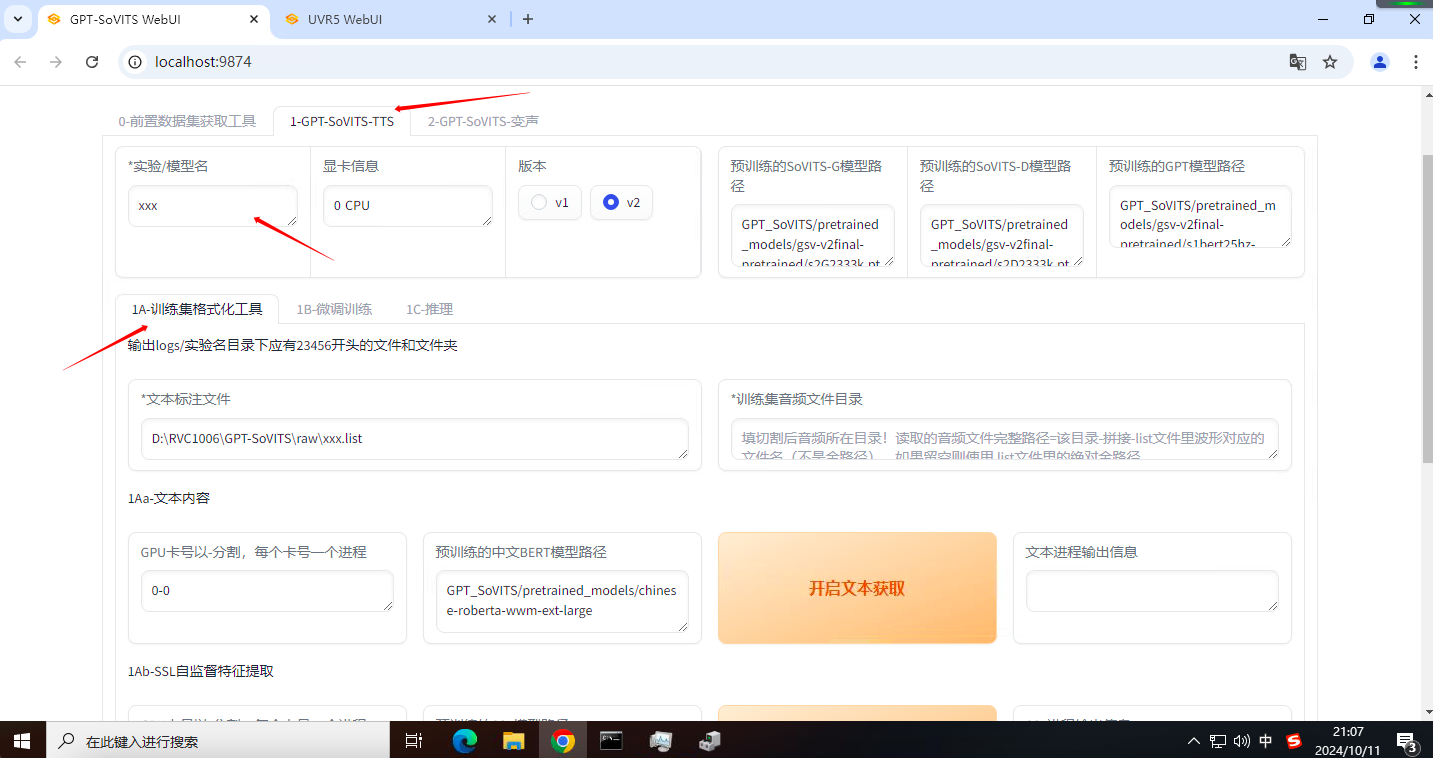
先设置实验名,这个就是最��后训练好的模型名。建议用英文。上一步对齐完成后,会自动填写路径,直接点最下面的“一键三连”就可以了。
3.5 微调
进入微调界面。
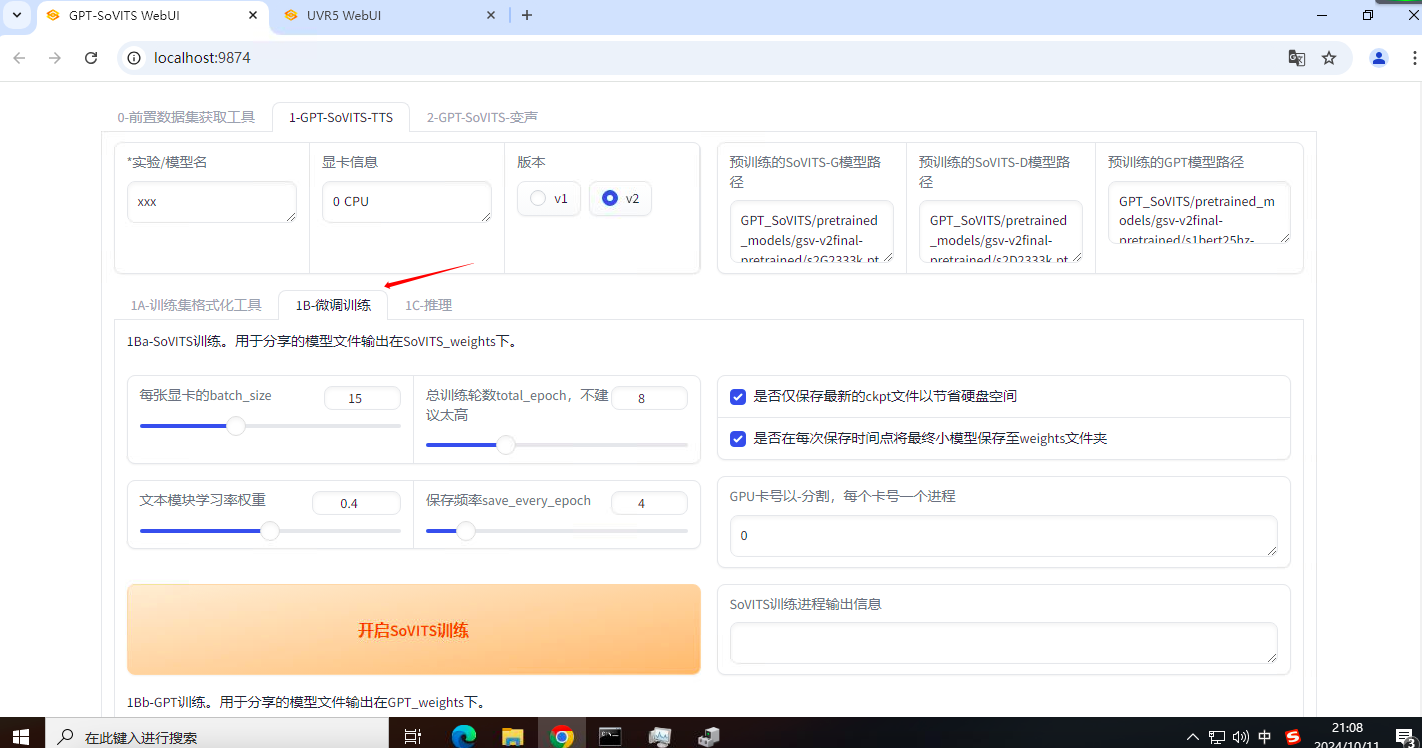
- batch_size:sovits训练建议batch_size设置为显存的一半以下,高了会爆显存。batch_size并不是越高越快,太高了反而会爆显存或者使用共享显存,反而会慢。
- dpo训练:dpo大幅提升了模型的效果,几乎不会吞字和复读,能够推理的字数也翻了几倍,但同时训练时显存占用多了2倍多,训练速度慢了4倍,12g以下显卡无法训练。数据集质量要求也高了很多。如果数据集有杂音,有混响,音质差,不校对标注,那么会有负面效果。
- 轮数:理论上轮数越高越接近原始音频数据,但是如果原始音频有杂音,电流音等问题,轮数太高反而会有负面效果。GPT模型轮数一般情况下不高于20,建议设置10。
先点开启SoVITS训练,训练完后再点开启GPT训练
3.6 文生音频
进入推理界面。
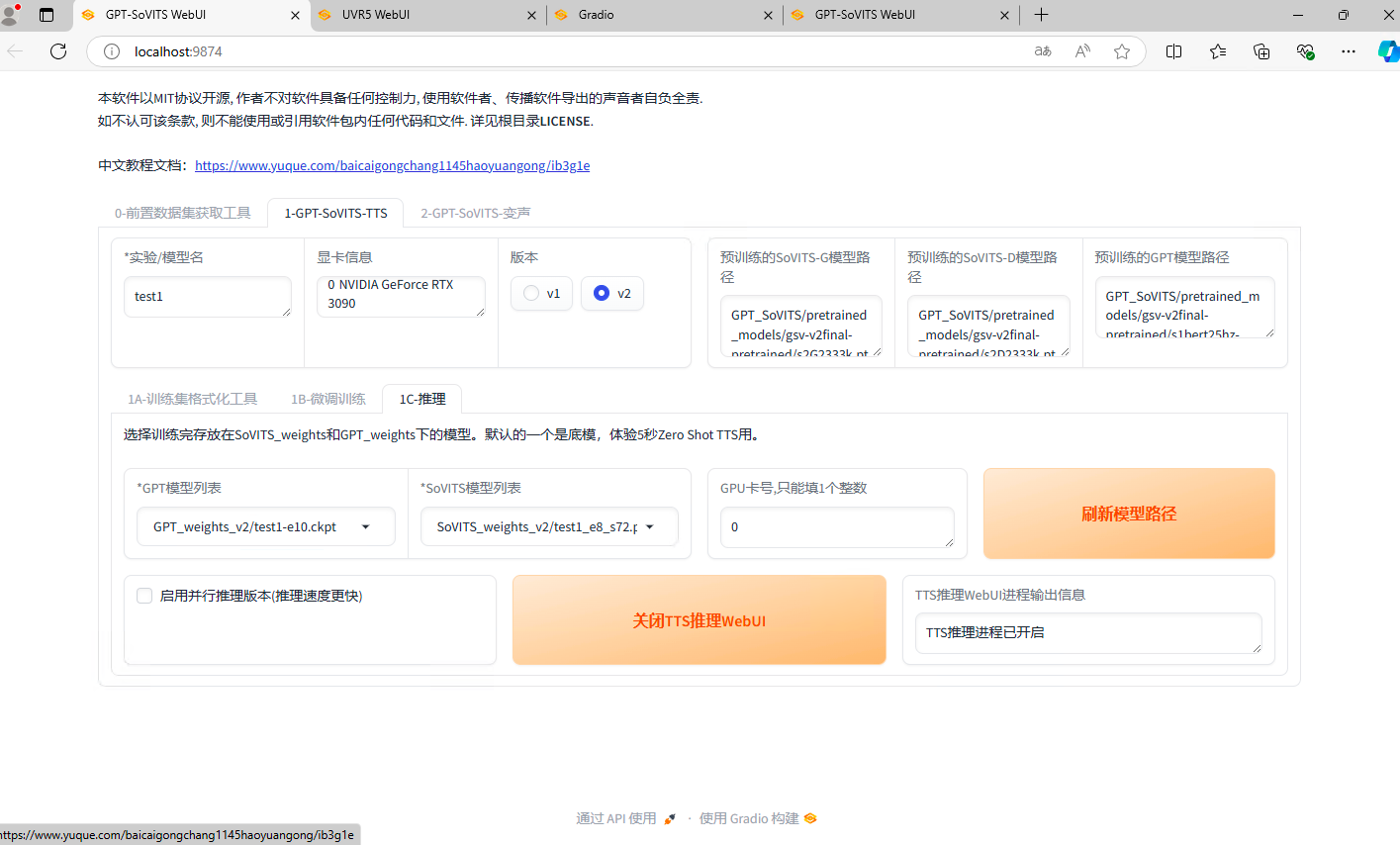
先点一下刷新模型,下拉选择模型推理,e代表轮数,s代表步数。不是轮数越高越好。选择好模型点开启TTS推理,自动弹出推理界面。如果没有弹出,复制控制台最下面的链接在浏览器里打开。
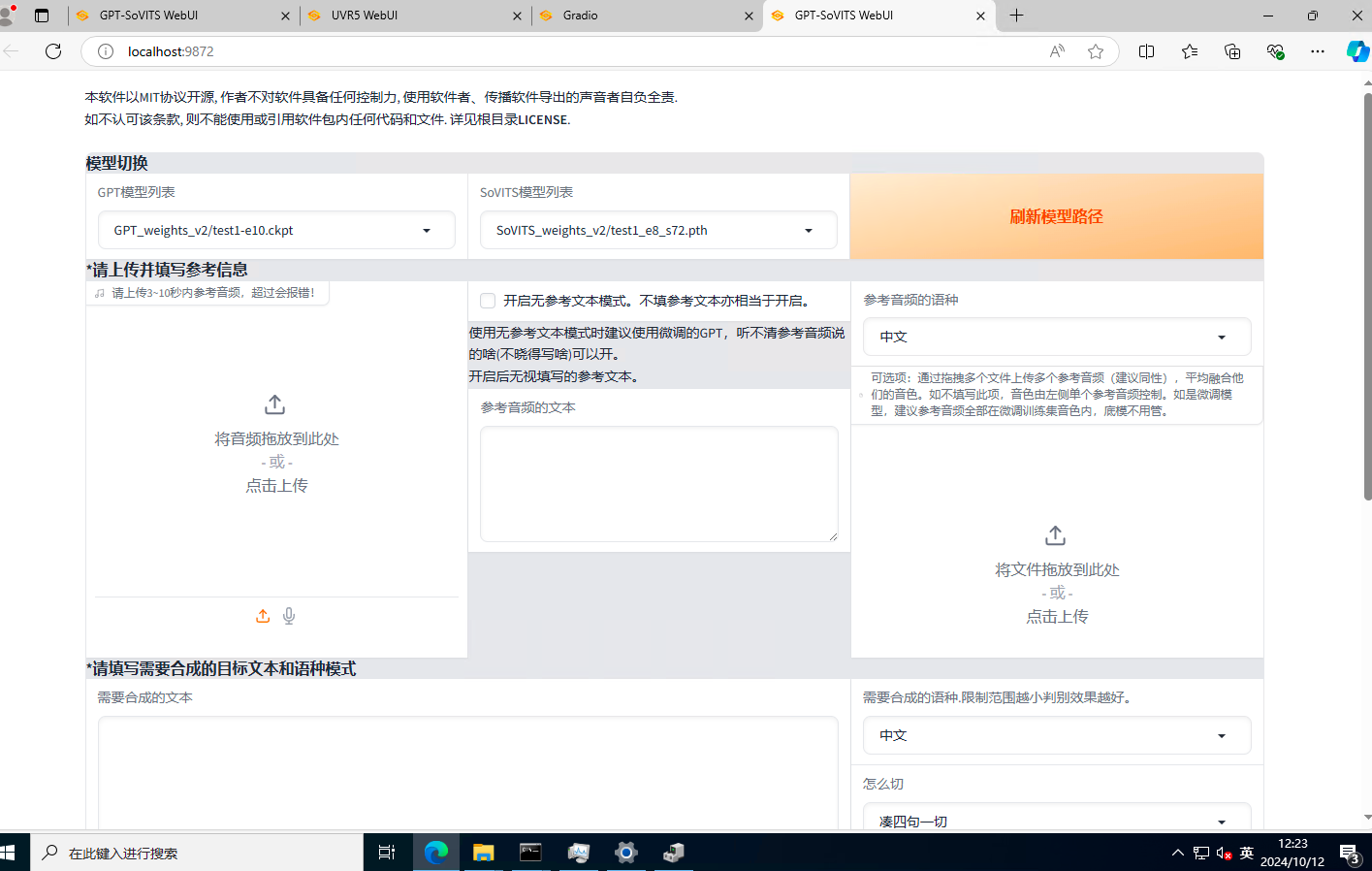
最上面可以切换模型,选择刚才训练出来的模型即可。然后上传一段参考音频,建议是数据集中的切割音频。最好5秒,并输入字幕。
模型会学习语速和语气,请认真选择。
其余参数的解释:
- 语种:选中文就好,目前可以中英混合
- 切分:切分建议无脑选凑四句一切,低于四句的不会切。如果凑四句一切报错的话就是显存太小了可以按句号切。
- top_p,top_k和temperature,保持默认就行了。
在要合成的文本输入框里输入想要合成的文案,然后点击“合成语音”就可以啦。
3.7 使用别人的模型
将GPT模型(ckpt后缀)放入GPT_weights_v2文件夹,SoVITS模型(pth后缀)放入SoVITS_weights_v2文件夹。双击go-webui.bat打开网页,再进入3.6文生音频,刷新下模型就能选择模型推理了。
4.常见问题
Q: 控制台为什么没有往下继续执行?
有的时候会卡住,多回车几次就好了