设置本地知识库
1.AnythingLLM
现在的AI大模型层出不穷,能力越来越强,但是在回答的专业性,数据的私密性上还不够完善,现在我们要创建本地知识库,让AI回答更加专业。
创建本地知识库,需要依赖向量数据库RAG技术。向量模型的作用是将文档信息转为特征向量,并存储在向量数据库中。相比较于常见的精确匹配,向量数据库擅长模糊匹配,例如我们搜索“小狗”,传统搜索很难命中“柯基”,“泰迪”等等,向量数据库则具备这样的能力。
通过向量模型,把文档信息转为向量数据库,这样我们在向大模型提问前,会先经过向量数据库查询相关信息,然后携带信息一起向大模型提问,这样看起来就像是大模型记住了我们提供的所有文档信息。
以前搭建这样的工具链还是比较复杂的,但是现在我们有方便的工具来帮助我们完成这一过程,那就是AnythingLLM。
AnythingLLM是一个桌面软件,他可以简化RAG工作流,使用本地模型或者公开模型的API,提供RAG服务API,但是他不提供像OpenWebUI那样的服务器页面。如果你最终需要在局域网内搭建私域的AI助手,还要参考: 如何搭建内网AI助手
先安装Docker,如果没有安装,可以参考: 在Linux上安装Docker
2.下载AnythingLLM
通过下面的链接下载anythingLLM安装包:
- Windows
- MacOS Intel芯片
- MacOS Apple芯片
- Linux终端
- Linux桌面端
3.安装AnythingLLM
- Windows
- MacOS Intel芯片
- MacOS Apple芯片
- Linux终端
- Linux桌面端
1.打开一个终端窗口,输入指令进入到下载目录 2.执行ls,确保文件夹里包含镜像文件,你应该看到
docker-images-anythingllm-tar.zip
3.执行下面的命令解压缩镜像文件
unzip docker-images-anythingllm-tar.zip
tar -xzvf x86-64-images.tar.gz
4.执行ls,确保文件里包含解压缩之后的镜像,他应该是.tar后缀的,例如
mintplexlabs_anythingllm-amd64.tar
5.使用docker加载镜像,执行
sudo docker load -i mintplexlabs_anythingllm-amd64.tar
你应该可以看到docker开始加载镜像,例如:
e0781bc8667f: Loading layer 77.83MB/77.83MB
8f8901bf8c60: Loading layer 9.539MB/9.539MB
5e4b20e815a6: Loading layer 35.33MB/35.33MB
8faf1c09f36d: Loading layer 4.608kB/4.608kB
Loaded image: mintplexlabs/anythingllm:latest
这样,你就成功将open webui的镜像加载进了docker容器中
- 执行下面的配置指令
export STORAGE_LOCATION=$HOME/anythingllm && \
mkdir -p $STORAGE_LOCATION && \
touch "$STORAGE_LOCATION/.env" && \
sudo docker run -d -p 3001:3001 \
--cap-add SYS_ADMIN \
-v ${STORAGE_LOCATION}:/app/server/storage \
-v ${STORAGE_LOCATION}/.env:/app/server/.env \
-e STORAGE_DIR="/app/server/storage" \
mintplexlabs/anythingllm
- 现在访问
http://localhost:3001就可以访问AnythingLLM了
4.设置向量数据库
- 安装完成之后,打开anythingLLM,点击左下角的设置
- 然后在LLM Preference里打开ollama,如果你的ollama已经在运行状态,可以看到他在监听默认的11434端口,这里保持默认不去修改,设置好模型和最大token后记得保存。
- 然后选择Embedding Model,依然选择Ollama,这里的向量模型选择nomic,这里的chunk length 是将文档分块的长度,通常设置为 256-512 个字符。设置过大会导致模型处理效率降低,设置过小则可能导致上下文丢失。
- 接下来我们选择vector database,可以选择默认的lanceDB作为向量数据库。
5.AnythingLLM的原理
我们来捋一下原理,当你想要和文档进行对话,
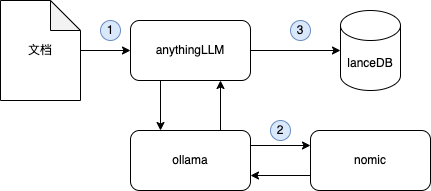
- 创建向量数据库:首先,你需要上传文档至 AnythingLLM。系统会将文档内容向量化(即将文本转为模型可理解的数值表示)。
- 存储向量数据:向量化的数据将被存储到 LanceDB 等向量数据库中。
- 结合搜索与大模型回答:每当用户提问时,系统会先从向量数据库中搜索相关文档段落,然后将其作为上下文提交给大模型进行回答。
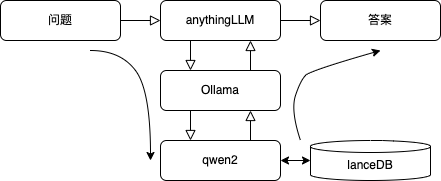
现在我们已经将文档全面向量化,现在我们向大模型提问,大模型将会带着你的问题去向量数据库中搜索相关内容,再结合搜索到的内容回答给出答案。
6.使用示例
下面我们来操作anythingLLM,
- 首先我们需要创建一个新的workspace工作空间。创建一个新的聊天,我们试试输入“你好”。
- 然后在这个窗口里上传文档这里我上传的是《2023年中国肥胖研究报告》,这篇报告统计了1500万中国人的体重,介绍了中国人的体重情况
- 下面我将导入这篇文档,选中,然后导入到workspace,记得点击保存。你需要等待一会儿,时长取决于你使用的是cpu还是gpu。
- 上传完毕后,我们点击设置,再点击聊天设置,将聊天模式改为查询,表示我们使用向量数据库里的知识,点击update workspace,保存生效。
- 现在我们尝试向他提问,“中国人的平均BMI是多少?”,可以看到他根据调查报告里的内容给出结论,位于23.5~24.5之间。
- 点击show citations,可以看到相应数据的出处。