Mac 安装指南
欢迎来到《Mac 安装指南》!🚀 在这里,你将学会如何在 Mac 上安装 Ollama 、 Open WebUI 以及 AnythingLLM 。让我们开始吧!🎉
- 系统版本:适配了绝大部分mac系统,实测12.7.5版本及以上即可
- 最少8GB内存
有问题?欢迎来淘宝店联系我们的 客服 💬
- 获取网盘提取密码 🔑
- 寻求人工指导 👩💻👨💻
完整的安装视频🎦:
1. 安装ollama
 ollama可以帮助我们非常方便的获取和运行大模型。
ollama可以帮助我们非常方便的获取和运行大模型。
安装ollama非常简单,可以按照以下步骤进行:
1.1 下载 ollama
使用下面的链接下载⬇️⬇️⬇️:
注意选择符合自己电脑的芯片版本进行下载。
- 点击左上角的苹果图标。
- 选择 "关于本机"。
- 在弹出的窗口中,会显示 Mac 的基本信息,包括处理器类型:
- 如果显示的是 “Apple M1” 或 “Apple M2”,则说明是 Apple 自研芯片。
- 如果显示的是 “Intel” 开头的处理器型号(如 “Intel Core i7”),则说明是 Intel 芯片。
1.2 安装ollama
下载完成之后解压,找到.dmg文件双击安装即可。
1.3.安装模型
- 启动一个终端窗口,输入以下命令来安装qwen:7b模型
ollama run qwen2
- 顺利的话,你应该可以从ollama的仓库里直接获取模型并安装。�例如:
pulling manifest
pulling 43f7a214e532... 1% ▕ ▏ 63 MB/4.4 GB 7.0 MB/s 10m21s
不能下载模型😵?或者想使用自定义模型🤔️?
如果遇到不能下载的问题,或者想要运行不在官方仓库里支持的模型,就要稍微麻烦一些。
1. 首先你需要手动下载模型
下面的链接是已经配置好的qwen7b模型,如果你需要更多其他模型可以联系我们。
- qwen:7b
- 更多模型
下载完成应该包含一个Modelfile文件和一个后缀名为gguf的模型文件
2. 安装模型
- 打开一个终端窗口,进入刚才下载的目录中,例如:
cd ~/Downloads/Qwen2-7B-F16
- 输入执行
ls,确保文件在该路径中,你应该看到:
Qwen2-7B-F16.gguf Modelfile
- 创建模型,执行
ollama create qwen2 -f Modelfile
这里的qwen2是自定义的模型名称,下面运行时还会用到
- 运行模型,执行
ollama run qwen2
你也可以在ollama的官网里找到它支持的其他模型⏬⏬⏬
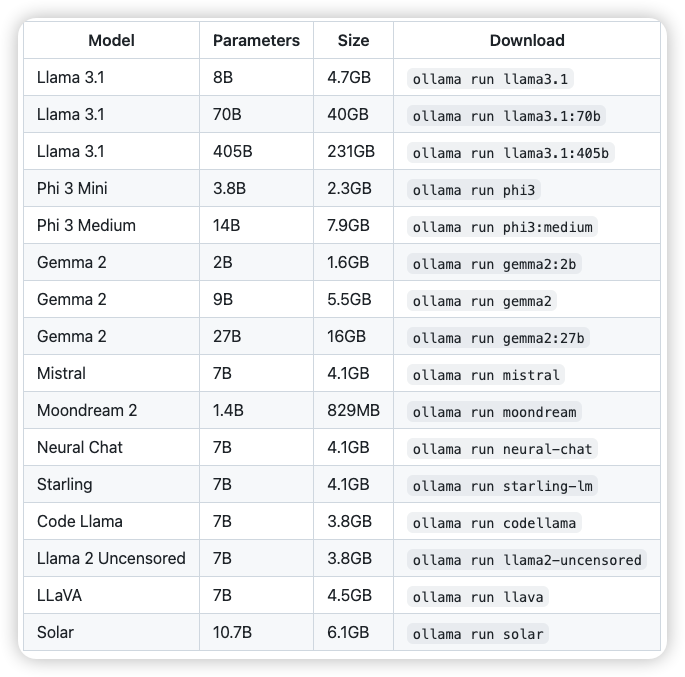
在这个列表里,你可以针对你的机器的内存大小,选择对应的版本,然后复制后面这一条命令就ok,一般来说7b的模型至少需要8G的内存,13b需要16G,70B需要64G内存,大家量力而行,不要过分选择太大的模型,不然跑起来真的非常慢。
这样,你就成功的在MacOS上安装并配置好了Ollama🎉🎉🎉
由于模型完全运行在本地,可以在断网的情况下运行,完全不担心数据泄漏的风险👍。
2. 安装 Docker 🐳
⚡️⚡️⚡️ 我们显然不满足仅仅使用命令行交互,这实在太原始了,我们还是想要有更现代,更好用的交互界面。
💥💥💥 Open WebUI可以快速的搭建聊天机器人的页面,而且可以一键集成ollama
🐳🐳🐳 不过想要安装Open WebUI,我们需要先安装Docker,简化我们的配置和安装环节。
2.1 下载Docker Desktop
- intel芯片
- apple芯片
2.2 安装Docker Desktop
下载完毕后,找到下载的.dmg文件双击安装。
2.3 启动Docker Desktop
双击Docker图标启动
2.4 验证安装
- 打开一个终端窗口,输入指令
docker --version确认安装已经完毕,你应该会看到Docker的版本信息,例如:
Docker version 20.10.8, build 3967b7d
这样,你就成功的在MacOS上安装并配置好了docker👏👏👏
下一步就是安装open-webui的镜像并运行
3.安装open webui
3.1 下载open webui的镜像
使用以下链接下载 Open WebUI 的镜像文件 ⬇️⬇️⬇️:
- Open WebUI 镜像
3.2 加载镜像 📥
-
解压镜像文件:
- 打开一个 终端窗口,进入到下载目录,例如:
cd ~/Downloads/docker-images-openwebui-tar - 查看文件列表,确保包含镜像文件:
你应该看到:
lsdocker-images-tar.zip - 解压缩镜像文件:
unzip docker-images-tar.zip
tar -xzvf x86-64-images.tar.gz - 再次查看文件列表,确保解压后的镜像文件存在:
你应该看到类似以下的
ls.tar文件:ghcr.io_open--webui_open-webui/main-amd64.tar
- 打开一个 终端窗口,进入到下载目录,例如:
-
加载镜像到 Docker:
- 确保 Docker Desktop 正在运行。
- 在 终端 中执行以下命令加载镜像:
docker load -i ghcr.io_open--webui_open-webui/main-amd64.tar - 你应该会看到类似如下的加载信息:
e0781bc8667f: Loading layer 77.83MB/77.83MB
8f8901bf8c60: Loading layer 9.539MB/9.539MB
...
Loaded image: ghcr.io/open-webui/open-webui:main
这样,你已经成功将 Open WebUI 的镜像加载到 Docker 中 📦✨。
3.3 运行镜像
继续在 终端 中输入以下命令来运行 Open WebUI 镜像:
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
-
docker run
启动一个新的 Docker 容器。 -
-d
这个选项让 Docker 容器以分离模式(detached mode)运行。也就是说,容器会在后台运行,而不会在终端中占用当前会话。
-p 3000:8080
这个参数映射端口:
- 3000 是宿主机(你的主机)上的端口。
- 8080 是容器内部的端口。 它的意思是将宿主机的 3000 端口映射到容器的 8080 端口,使外部可以通过 http://localhost:3000 访问容器内的服务(假设服务运行在 8080 端口)。
--add-host=host.docker.internal:host-gateway
这个选项添加了一个自定义的 DNS 映射:
- host.docker.internal 是在容器内可以访问宿主机的别名。
- host-gateway 是一个特殊的标识符,让 host.docker.internal 指向宿主机的 IP 地址。这样容器内部可以通过 host.docker.internal 访问宿主机。
-v open-webui:/app/backend/data
这个选项挂载一个卷(volume):
- open-webui 是宿主机上的卷。
- /app/backend/data 是容器内部的路径。 它的意思是在容器内的 /app/backend/data 目录与宿主机的 open-webui 卷挂载一起,以便持久化存储数据,并且在容器重启后数据不会丢失。
--name open-webui
这个参数设置容器的名字为 open-webui。设置一个名字便于管理和操作容器,如启动、停止等。
--restart always
这个选项设置容器的重启策略:
always 表示无论容器为何退出,Docker 都会自动重启它。这对于需要高可用的服务非常有用。
ghcr.io/open-webui/open-webui:main
这是镜像的名称和标签:
- ghcr.io 是 GitHub Container Registry 的域名。
- open-webui/open-webui 是镜像的仓库名称。
- main 是镜像的标签,通常表示主分支或是最新的稳定版本。
综上所述,这条 docker run 命令启动了一个名为 open-webui 的容器,它会在后台运行,将宿主机的 3000 端口映射到容器的 8080 端口,挂载一个持久化存储卷,并且无论何种原因导致容器退出,Docker 都会自动重启这个容器。容器内的服务可以通过 host.docker.internal 访问宿主机。
你应该会看到类似如下的输出,表示容器已成功启动:
% docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
a09512f358ee3c497543b3103878b1f06c89d0c956ba542baf58fb2e067f4727
3.4 访问 Open WebUI 🌐👀
打开你的浏览器,访问 http://localhost:3000。你应该会看到 Open WebUI 的界面,如下所示:
这个Open WebUI 除了具备基本的聊天功能之外,还 RAG(检索增强生成)能力,不管你是网页还是文档,都可以作为参考资料给到大模型,你如果想让大模型读取网页的话,那在链接前面加个‘#’号就行
你如果想让大模型读取文档的话,可以在对话框的位置倒入,在对话框页面输入#就会出现已经导入的所有文档,你可以选择一个,或者干脆让大模型把所有文档都作为参考资料.
如果你的要求不太高,那做到这一步就OK了,如果你对知识库想有更多的掌控的话,那再去下载anythingLLM,去做更多进阶的操作:
如果你想将ollama设置为服务器模式,在内网搭建AI助手的服务器,那再去看这份指南: